2022 SCIEN Affiliates Meeting Distinguished Poster Awards
| Company | Poster | |
|---|---|---|
| Apple | Title: MantissaCam: Learning Snapshot High-dynamic-range Imaging with Perceptually-based In-pixel Irradiance Encoding Authors: Haley M. So, Julien N. P. Martel, Piotr Dudek, Gordon Wetzstein Abstract: The ability to image high-dynamic-range (HDR) scenes is crucial in many computer vision applications. The dynamic range of conventional sensors, however, is fundamentally limited by their well capacity, resulting in saturation of bright scene parts. To overcome this limitation, emerging sensors offer in-pixel processing capabilities to encode the incident irradiance. Among the most promising encoding schemes is modulo wrapping, which results in a computational photography problem where the HDR scene is computed by an irradiance unwrapping algorithm from the wrapped low-dynamic-range (LDR) sensor image. Here, we design a neural network-based algorithm that outperforms previous irradiance unwrapping methods and we design a perceptually inspired “mantissa,” or log-modulo, encoding scheme that more efficiently wraps an HDR scene into an LDR sensor. Combined with our reconstruction framework, MantissaCam achieves state-of-the-art results among modulo-type snapshot HDR imaging approaches. We demonstrate the efficacy of our method in simulation and show benefits of our algorithm on modulo images captured with a prototype implemented with a programmable sensor. Bio: Haley So is a 3rd year PhD student researching in Professor Gordon Wetzstein’s Computational Imaging Lab. She is interested in the co-design of hardware and software, particularly in utilizing emerging sensors to rethink imaging algorithms and computer vision tasks. |  |
| Title: Learning Spatially Varying Pixel Exposures for Motion Deblurring Authors: Cindy M. Nguyen, Julien N.P. Martel, Gordon Wetzstein Abstract: Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor–processors along with an end-to-end design of these exposures and a machine learning–based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Bio: Cindy Nguyen is a fourth-year PhD student, advised by Gordon Wetzstein in the Stanford Computational Imaging lab. Her background is in task-specific end-to-end camera design, including systems for single-shot monocular depth estimation and motion deblurring. She is interested in imaging problems around depth estimation, deblurring, denoising, and HDR. | 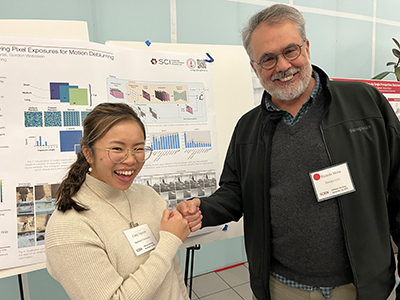 |
|
| Intuitive | Title: Ultralight Night Vision Imaging System Without External Power Supply Authors: Manchen Hu, Emma Belliveau, Natalia Murrietta, Pournima Narayanan, Dan Congreve Abstract: Night vision today is generally enabled by high-voltage image intensifier tubes, which convert photons into an electron cascade that ultimately converts into sufficiently bright visible light via a phosphor screen. This approach requires high external power and a large length of intensifier tubes. Passive, linear upconversion of light from the infrared into the visible holds the powerful potential to revolutionize night vision—reducing the size and weight of night-vision systems and obviating the need for external power. In this work, combining the innovative designs of semiconductor materials and optoelectronic device structures, we successfully demonstrated the prototype of an ultralight night vision imaging system that enables sight over a broadband range in the near-infrared (NIR). This system, without any power supply, can convert NIR into visible light/images that can be seen by the naked eyes. Bio: Manchen Hu is a Ph.D. candidate in the Department of Electrical Engineering at Stanford University. Machen’s research in Professor Dan Congreve’s Lab deals with thin-film optoelectronic devices that can upconvert infrared photons into visible photons. He is interested in light-matter interactions and works on the combination of optics, electronics, and materials to enable novel functionality of the devices. |  |
| Microsoft | Title: A Photoacoustic Airborne Sonar System Authors: Aidan Fitzpatrick, Ajay Singhvi, Amin Arbabian Abstract: Sonar imaging allows for exploration of areas of the ocean that are not readily accessible for direct observation albeit at a slow rate. To overcome the limitations of sonar, there is a push to develop an airborne system that can increase the speed and thus spatial coverage of underwater imaging. We present a system concept which maintains the advantages of conventional in-water sonar while operating entirely from an airborne platform. The proposed system translates airborne optical excitation into an underwater acoustic source through the laser-induced photoacoustic effect and employs air-coupled ultrasound transducers to detect acoustic echoes from the underwater scene. By combining the unique advantages of light and sound, our system could make oceans transparent and enable large-scale, high-throughput underwater sensing. Bio: Aidan Fitzpatrick received the B.S. degree in electrical and computer engineering from the University of Massachusetts Amherst in 2018, where he performed research on antenna design and RF system design, and the M.S. degree in electrical engineering from Stanford University in 2020, where he is currently pursuing the Ph.D. degree in electrical engineering. His research interests are in computational imaging and perception systems—specifically at the intersection of electromagnetics, acoustics, and signal processing for the co-design of imaging algorithms and system hardware. His current projects focus on remote sensing applications of non-contact thermoacoustic/photoacoustic imaging. | 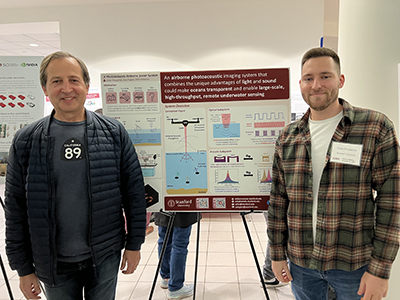 |
| OPPO | Title: Seeing Far in the Dark with Patterned Flash Authors: Zhanghao Sun, Yicheng Wu, Jian Wang, Shree Nayar Abstract: Flash illumination is widely used in imaging under low-light environments. However, illumination intensity falls off with propagation distance quadratically, which poses significant challenges for flash imaging at a long distance. We propose a new flash technique, named “patterned flash”, for flash imaging at a long distance. Patterned flash concentrates optical power into a dot array. Compared with the conventional uniform flash where the signal is overwhelmed by the noise everywhere, patterned flash provides stronger signals at sparsely distributed points across the field of view to ensure the signals at those points stand out from the sensor noise. This enables post-processing to resolve important objects and details. Additionally, the patterned flash projects texture onto the scene, which can be treated as a structured light system for depth perception. Given the novel system, we develop a joint image reconstruction and depth estimation algorithm with a convolutional neural network. We build a hardware prototype and test the proposed flash technique on various scenes. The experimental results demonstrate that our patterned flash has significantly better performance at long distances in low-light environments. Bio: Zhanghao Sun is a 5th year PhD student at Electrical Engineering, Stanford University. He works mainly in the field of computational imaging hardware and algorithms. He’s advised by Prof. Olav Solgaard, and co-advised by Prof. Gordon Wetzstein. | 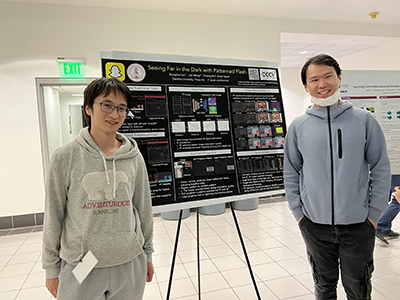 |
| Rivian | Title: Vitruvio: 3D Building Meshes via Single Perspective Sketches Authors: Alberto Tono, Martin Fischer Abstract: Today’s architectural engineering and construction (AEC) software require a steep learning curve to generate a three-dimension building representation. This limits the ability to quickly validate the volumetric implications of an initial design idea communicated via a single sketch. Allowing designers to translate a single sketch to a 3D building will enable owners to instantly visualize 3D project information without the cognitive load required. If previous state-of-the-art (SOTA) methods for single view reconstruction (SVR) showed outstanding results in data-driven reconstruction processes from a single image or sketch, they lacked specific applications, analysis, and experiments in the AEC. Therefore, this research addresses this gap, introducing a deep learning method: Vitruvio. Vitruvio adapts Occupancy Network for SVR tasks on a specific building dataset (Manhattan 1K). This adaptation brings two main improvements. First, it accelerates the inference process by more than 26\% (from 0.5s to 0.37s). Second, it increases the reconstruction accuracy (measured by the Chamfer Distance) by 18\%. During this adaptation in the AEC domain, we evaluate the effect of the building orientation in the learning procedure since it constitutes an important design factor. While aligning all the buildings to a canonical pose improved the overall quantitative metrics, it did not capture fine-grain details in more complex building shapes (as shown in our qualitative analysis). Finally, Vitruvio outputs a 3D-printable building mesh with arbitrary topology and genus from a single perspective sketch, providing a step forward to allow owners and designers to communicate 3D information via a 2D, effective, intuitive, and universal communication medium: the sketch. Bio: Tono Alberto is a current PhD Student at Stanford University under the supervision of Kumagai Professor Martin Fischer. Furthermore, as president of the Computational Design Institute, he is exploring ways in which the Convergence between Digital and Humanities can facilitate cross-pollination between different industries within an Ethical Framework. He served as the Research and Computational Design Leader in Architectural and Engineering organizations, receiving the O1-visa for outstanding abilities with both HOK and HDR. Tono obtained his Masters in Building Engineering – Architecture from the University of Padua and the Harbin Institute of Technology. He has been working in the computational design and deep learning space since 2014. Furthermore, he is improving Building Information Modeling and Virtual Design and Construction (BIM/VDC) workflows within a statistical framework to optimize the sustainability impact of these processes. Hence, Tono is LEED AP certified. He is an international multi-award-winning “hacker” and speaker, and his work within Architecture and Artificial Intelligence brought him to companies in China, the Netherlands, Italy, and California. Thanks to his multidisciplinary approach he worked as Data Scientist and Geometric Deep Learning Researcher at a Physna/Thangs helping to raise over 80 Milion while working on 3D Search and Monocular 3D Shape Retrieval problems. He is devoting his life for Hannah Tono’s happiness. Since they b oth are passionate about new technologies, he developed an augmented reality wedding proposal. Together they run a program called Dreamship to help Pediatric Palliative Care Hospices adopt immersive technologies through research. | |
| Samsung | Title: Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators Authors: Suyeon Choi, Manu Gopakumar, Jonghyun Kim, Yifan Peng, Matthew O’Toole, and Gordon Wetzstein Abstract: Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence–driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of near-eye holographic displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment. Bio: Suyeon Choi is a third-year PhD student working as a part of Stanford Computational Imaging Lab, advised by Prof. Gordon Wetzstein. He is generally interested in developing 3D display hardware systems with novel algorithmic frameworks. Lately, he has been developing holographic display systems incorporating machine learning toward next-generation VR/AR displays. His research has been partly supported by a Meta Research PhD Fellowship, a Kwanjeong Scholarship, a Korean Government Scholarship, and a GPU gift from NVIDIA. |  |
| SkHynix | Title: Generative Neural Articulated Radiance Fields Authors: Alexander W. Bergman, Petr Kellnhofer, Wang Yifan, Eric R. Chan, David B. Lindell, Gordon Wetzstein Abstract: Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations. Bio: Alexander W. Bergman is a fifth year PhD student in the Stanford Computational Imaging Lab. His research interests include neural rendering and 3D imaging. | 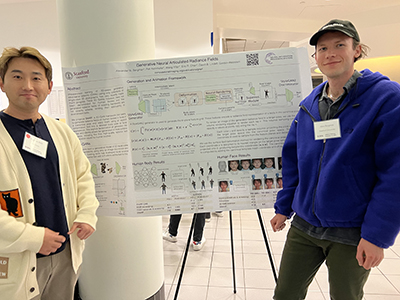 |
| Starkey Hearing Technologies | Title: 3D quantitative-amplified Magnetic Resonance Imaging (3D q-aMRI) Authors: Itamar Terem, Nan Wang, Kyan Younes, Hillary Vossler, Elizabeth Mormino, Smantha Holdsworth and Kawin Setsompop Abstract: Amplified Magnetic Resonance Imaging (aMRI) is a pulsatile brain motion visualization method that delivers ‘videos’ with high contrast and temporal resolution. aMRI has been shown to be a promising tool in various neurological disorders. However, aMRI currently lacks the ability to quantify the sub-voxel motion field in physical units. Here, we introduce a novel 3D quantitative aMRI (3D q-aMRI) algorithm, which quantifies the sub-voxel motion of the 3D aMRI signal. 3D q-aMRI is validated on a digital phantom and in-vivo model, which may open up applications in neurological conditions that benefit from understanding altered patterns of brain motion. Bio: Itamar Terem is a PhD student at the department of Electrical Engineering at Stanford University, and an NSF Graduate Research Fellow. His research focuses on the development of computational and acquisition MRI techniques to explore the cerebrospinal fluid (CSF) dynamic (drivers and motion) through the brain ventricular system, subarachnoid and perivascular space in awake and sleep. |  |
| Synopsys | Title: Generative Novel View Synthesis with 3D-Aware Diffusion Models Authors: Eric Ryan Chan, Koki Nagano, Jeong Joon Park, Matthew Chan, Alexander William Bergman, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, Gordon Wetzstein Abstract: We present a diffusion-based model for 3D-aware generative novel view synthesis from one or more input images. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse, high-fidelity, and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, we incorporate geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method’s ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent images. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects. Bio: I’m Eric, a first-year Ph.D. student at Stanford where I’m advised by Gordon Wetzstein and Jiajun Wu. After studying mechanical engineering and computer science at Yale, I began learning the basics of computer vision in the hope of teaching robots and algorithms how to better understand the world around them. Over the last couple of years, my focus has shifted to the intersection of 3D graphics and vision—to generalization across 3D representations and 3D generative models. Find more at ericryanchan.github.io |  |